
Powrót do: Teaching – Analiza języka i mowy
I. Nagrania
Nagrania: Proszę nagrać po dwie lub trzy własne realizacje każdej z polskich samogłosek, w izolacji. Dodatkowo proszę też zarejestrować wypowiedzi tych samych samogłosek w sylabach otwartych, gdzie na pierwszym miejscu stoi spółgłoska. Najlepiej jeśli bodźce podczas czytania będą pojawiały się w kolejności losowej i we względnie równych odstępach czasowych (2018 – zajęcia w studio, nagrania w programie Audacity, bodźce prezentowane za pomocą programu Open Sesame).
II. Anotacja
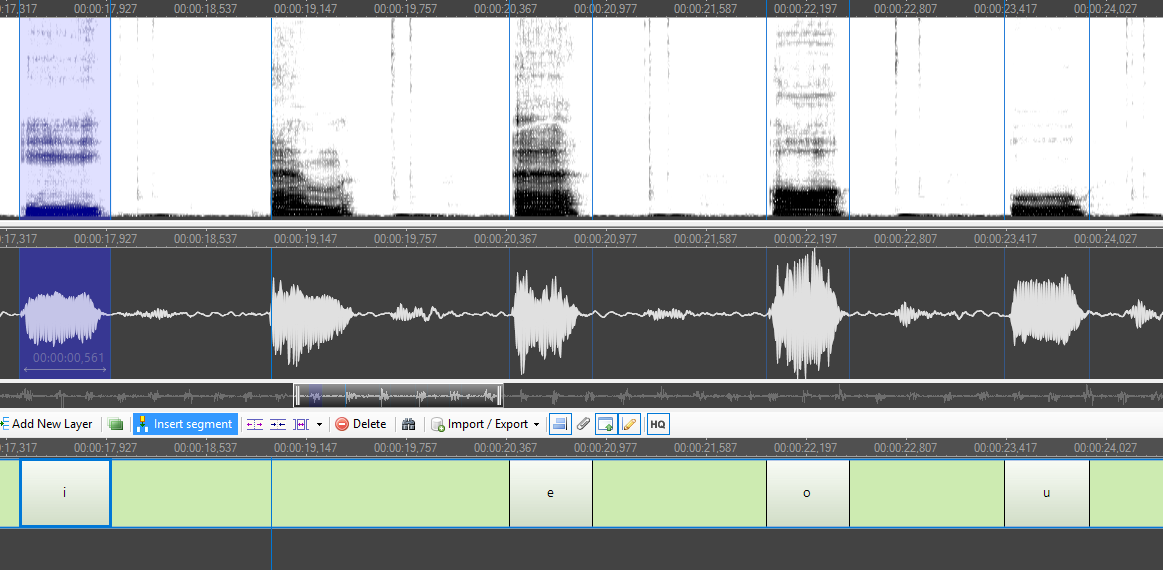
Proszę wyodrębnić na warstwie anotacji w programie Annotation Pro realizacje samogłosek w izolacji. Pozostałych realizacji nie trzeba segmentować. Dla wyjaśnienia: to, że na liście bodźców znalazły się tez inne elementy miało 2 powody:
- urozmaicenie realizowanego zestawu wypowiedzi (unika się w ten sposób znużenia mówcy i tzw. torowania)
- dostarczenie Państwu materiału poglądowego, tak by w czasie anotacji mogli Państwo zaobserwować na spektrogramach specyficzne cechy samogłosek realizowanych w izolacji i w sylabach zawierających spółgłoskę
III. Pomiar f0
Sposób 1. Praat
Jeśli anotacja była wykonana w Annotation Pro, proszę wyeksportować anotację do TextGrid i otworzyć w Praat (wav i ten TextGrid).
Proszę dokonać pomiaru częstotliwości podstawowej f0 w programie Praat kolejno dla anotowanych głosek, a następnie obliczyć wartość średnią, minimalną i maksymalną (najpierw należy wyświetlić wykres pitch, korzystając z menu Pitch->Show pitch, a następnie pobrac wyniki pomiarów za pomocą menu Pitch -> Get Pitch i odpowiednio: -> Get minimum Pitch, -> Get maximum Pitch).
Sposób 2. Annotation Pro – eksport f0 dla samogłosek
Proszę dokonać pomiaru częstotliwości podstawowej f0 w Annotation Pro (menu Analysis -> Fundamental Frequency Estimation). Następnie proszę wpisać wyniki pomiaru jako parametr segmentów z anotacją samogłosek, wykorzystując w tym celu plugin do pobrania TUTAJ. Plugin należy najpierw rozpakować i umieścić w katalogu Annotation Pro -> Plugins. Pojawi się on w menu programu Plugins (może być konieczne odświeżenie tego menu). Po wyeksportowaniu warstwy do .CSV możliwe będzie obliczenie średnich, wartości minimalnych i maksymalnych f0 dla samogłosek w arkuszu kalkulacyjnym.

IV. Pomiary formantów samogłoskowych
Sposób 1. Praat
Proszę dokonać pomiaru częstotliwości formantowych w programie Praat kolejno dla anotowanych głosek, a następnie obliczyć wartość średnią (najpierw należy wyświetlić wykresy formantów, korzystając z menu Formants->Show formants, a następnie pobrac wyniki pomiarów za pomocą menu Formants->Formants listing). Te dane przenosimy kolejno do arkusza kalkulacyjnego i tam wyliczamy wartości średnie formantów. Praat dostarcza nam informacji o wartościach czterech formantów: F1, F2, F3, F4.
Sposób 2. Pomiar w programie Praat i generowanie arkusza średnich za pomocą pluginów Annotation Pro
a) Proszę posegmentować plik z nagraniem na głoski/sylaby, używając Annotation Pro. W przypadku, gdy nagrania przeprowadzono w studio, z użyciem e-Prime, wystarczy zaimportować dane z pliku .CSV (gdzie znajduje się informacja w trzech kolumnach: label, czas-start, czas-stop) i sprawdzić segmentację, wyrównując położenie granic a razie konieczności. Uwaga: jeśli w obrębie segmentu słychać uderzenie spacji lub inne szumy, proszę postawić granicę tak, aby segment z bodźcem nie obejmował tego szumu. Jeśli na sam bodziec nakłada się jakieś zaklócenie – usuwamy odpowiadający mu segment z warstwy anotacji, taki segment nie będzie uwzględniony w późniejszej analizie.
b) Eksportujemy dane do formatu TextGrid (format programu Praat).
c) W programie Praat otwieramy plik wave z naszym nagraniem i odpowiadający mu TexGrid (otrzymany w wyniku eksportu). Open -> Read from File, następnie zaznaczamy oba na liście obiektów i wybieramy: View & Edit
d) Dokonujemy pomiaru formantów i zapisujemy wyniki np. pobierając tzw. Formant listing:
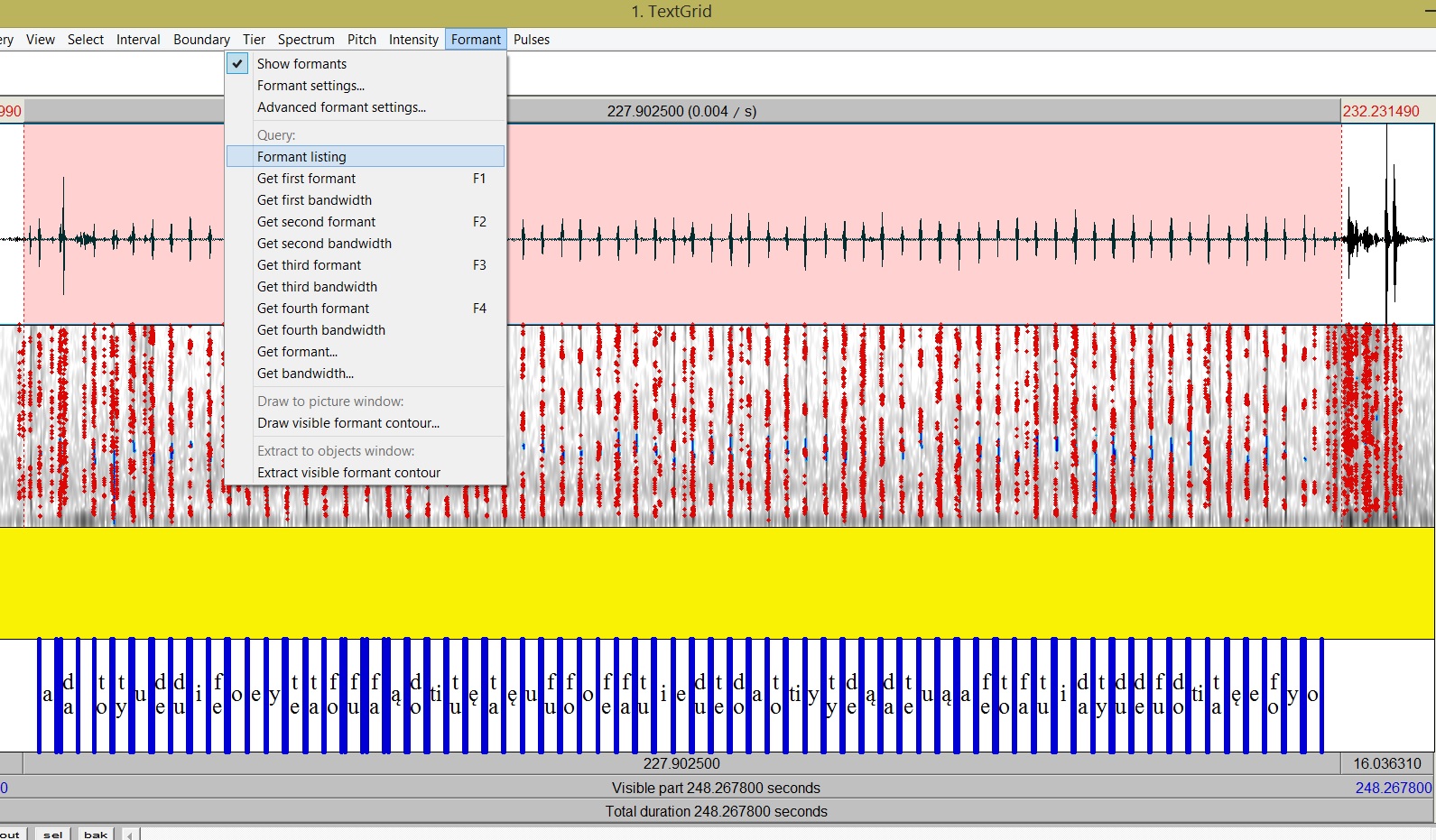
W przypadku pobierania listing dla dłuższego nagrania, może to zająć dłuższą chwilę, należy poczekać. Czasem trzeba też ustawić w Praacie zakres dla którego wyświetlane są formanty (domyślnie na dużym zoo-out nie są one pokazywane), ustawienia wyświetlania dostępne są w menu View->Show Analyses. Następnie zapisujemy Formant listing do pliku tekstowego.
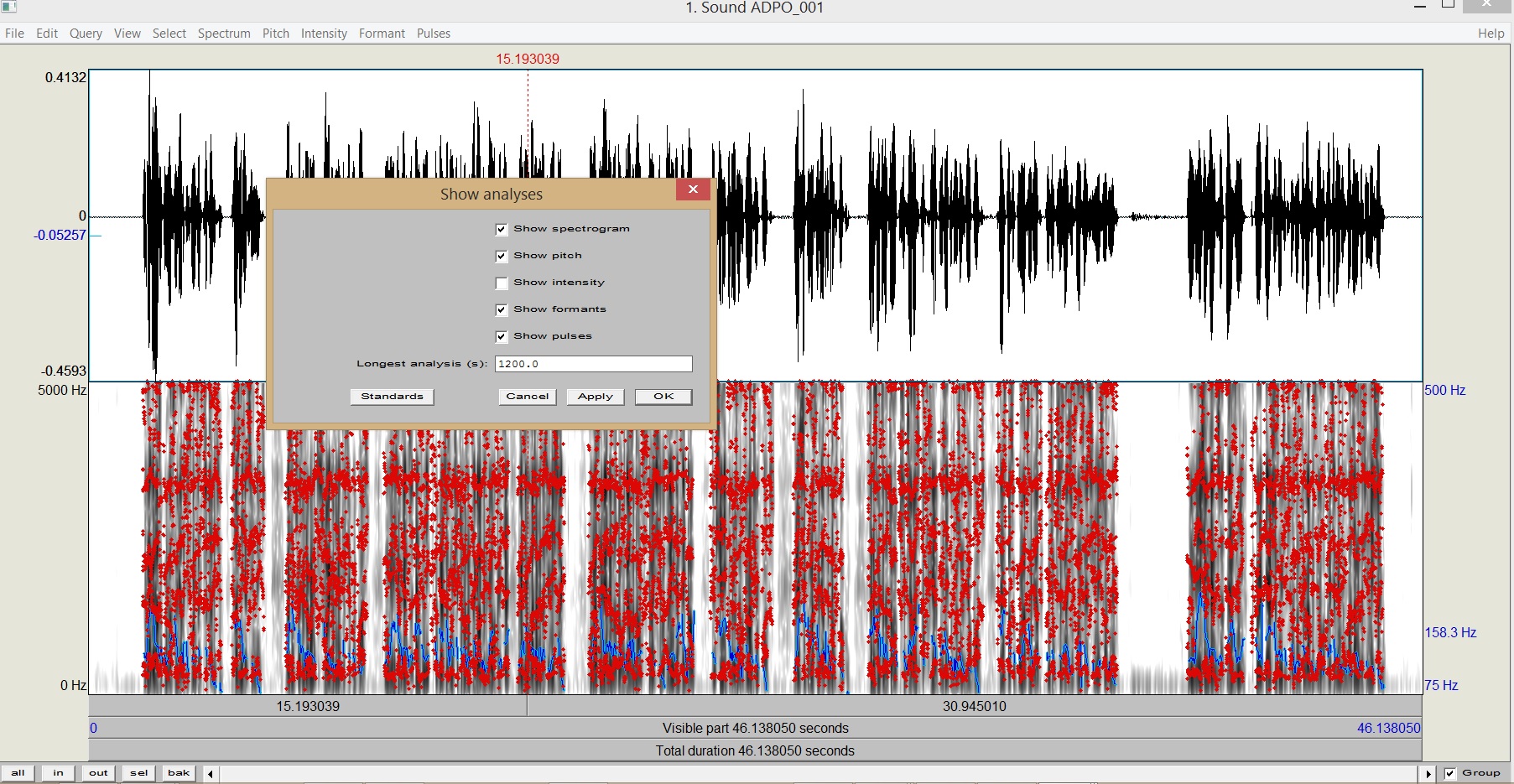
e) Importujemy dane z Formant listing na warstwę programu Annotation Pro. Przy imporcie proszę pamiętać o ustawieniu separatora dziesiętnego (musi być taki jak w ustawieniach Annotation Pr.o)
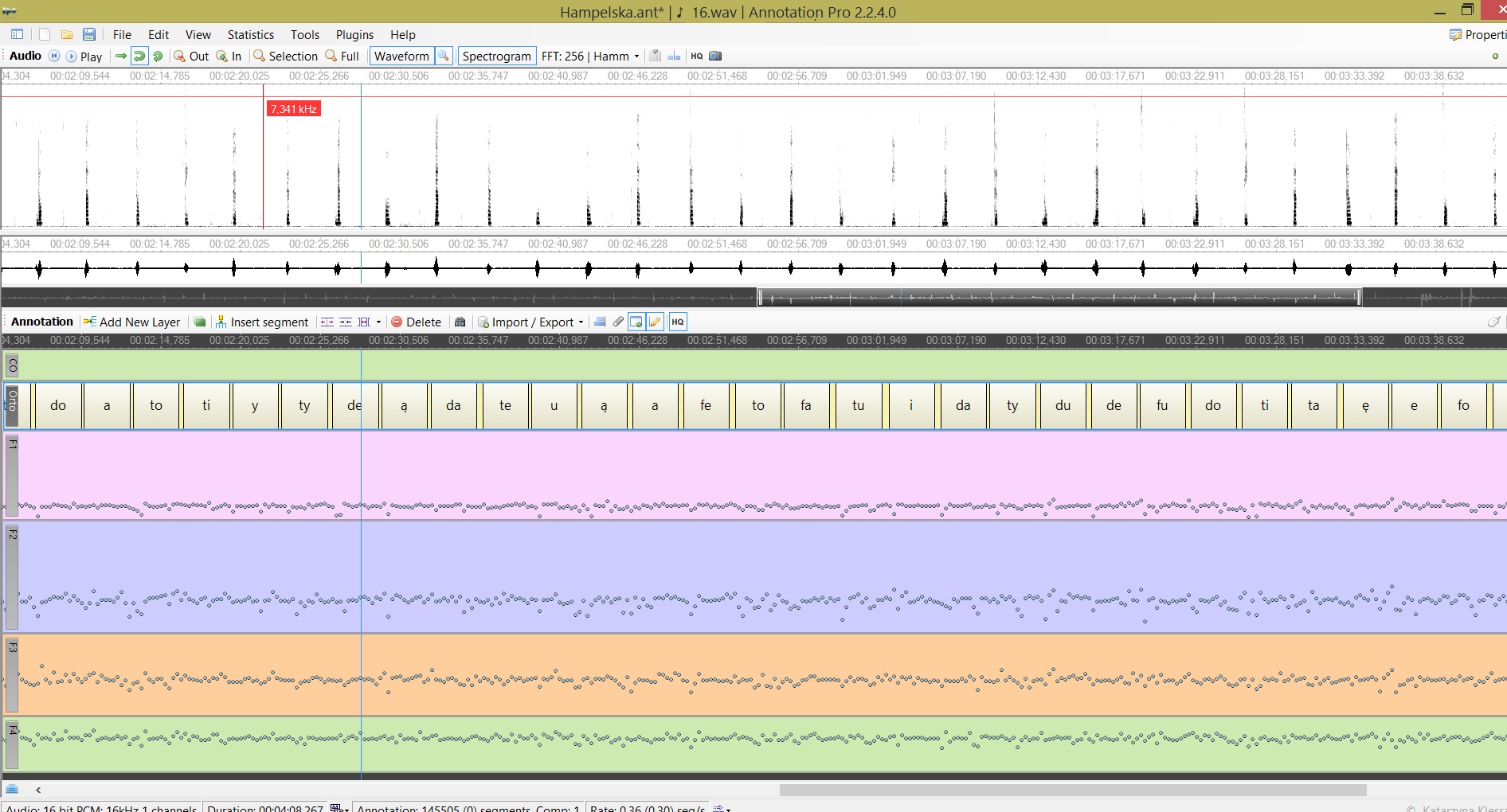
Na warstwie Annotation Pro formanty wyświetlają się albo jako wykres (chart), albo jako liczby, zależnie od ustawień. Chart działa szybciej w przypadku dużej ilości punktów.
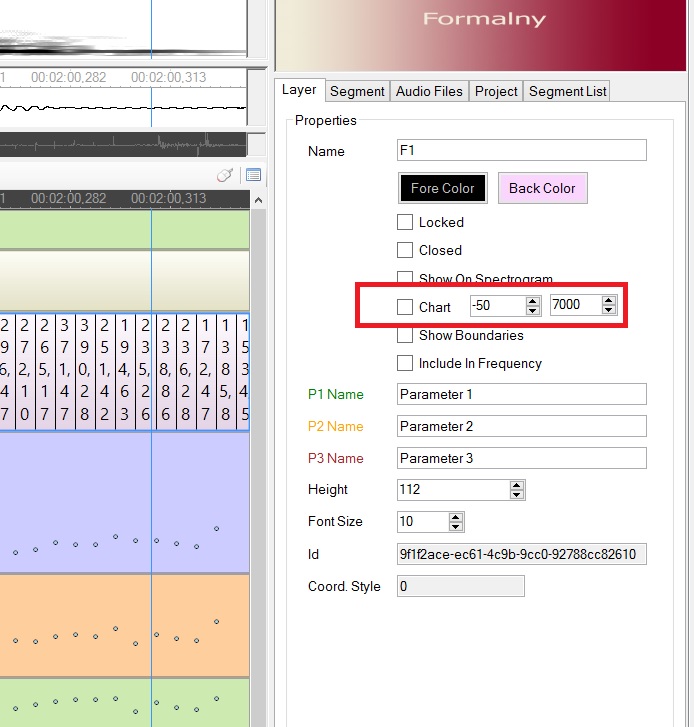
f) proszę zduplikować warstwę z segmentacją wg bodźców i jedną z nich nazwać stimuli_F1, a drugą stimuli_F2
g) za pomocą pluginów F1 Parameters#2_Copy f1 to_Parameter1.cs F2 Parameters#2_Copy f2 to_Parameter2.cs (tutaj) wpisujemy wartości formantów F1 i F2 do parametru odpowiednich głosek na warstwie z segmentacją wg bodźców.
h) za pomocą pluginów Statistics#Average Parameter_ for f1.cs i Statistics#Average Parameter_for_f2.cs (tutaj) lub w arkuszu kalkulacyjnym (np. z użyciem tabeli przestawnej) obliczamy średnie wartości formantów F1 i F2 dla segmentów.
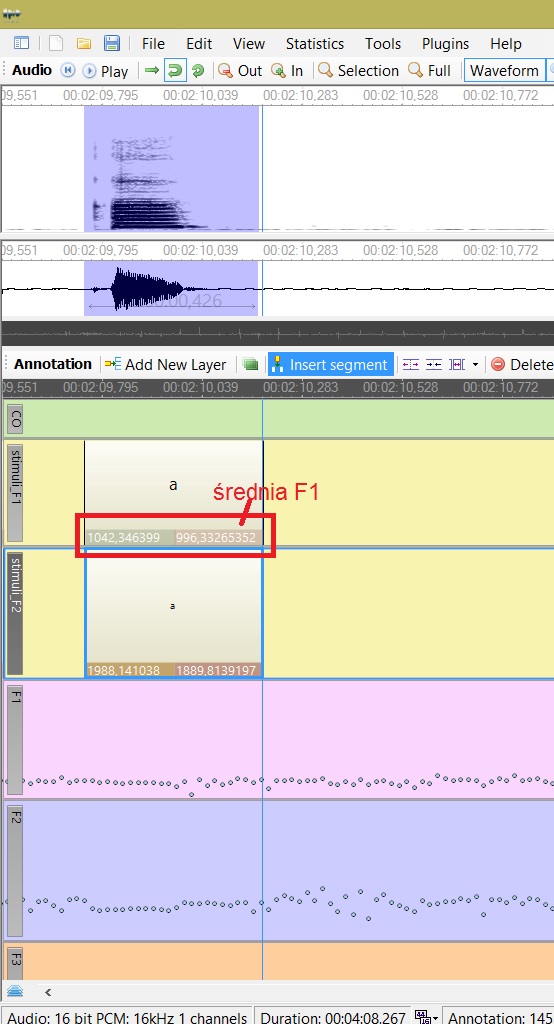
h) eksportujemy warstwy stimuli_F1 i stimuli_F2 do formatu .CSV, a potem do arkusza kalkulacyjnego (separator kolumny to TAB), tam odfiltrowujemy tylko izolowane samogłoski w celu wykreślenia wykresu na płaszczyźnie F2-F1.
Sposób 3. Pomiar formantów w programie Wavesurfer (na zajęciach do r. 2013/14)
Proszę dokonać pomiaru formantów samogłoskowych F1 i F2 w nagranych głoskach, używając programu Wavesurfer. Pomiaru formantów dokonujemy w najbardziej ustabilizowanym miejscu głoski, zwykle mniej więcej w jej środku. Wavesurfer umożliwia zarówno pomiar w punkcie jak i uśredniony pomiar dla zaznaczonego fragmentu nagrania. W celu uzyskania bardziej miarodajnych wyników należy albo wykonać kilka pomiarów w kilku punktach w określonych odstępach, a następnie uśrednić wynik albo zaznaczyć dłuższy fragment i dla niego dokonać pomiaru. Na potrzeby obecnego ćwiczenia proszę dokonać pomiaru dla fragmentu ok. 30 ms w środku każdej samogłoski;
Poniżej przedstawiono na zdjęciach najważniejsze kroki w pomiarze formantów w Wavesurfer:

Krok 1. Należy utworzyć panel “Formant plot”, na którym wyświetlą się kolorowe krzywe dla 4 formantów.

Kroki 2 i 3. Należy zaznaczyć myszką wybrany fragment samogłoski, a następnie kliknąć na nim prawym klawiszem myszki (koniecznie na panelu “Formant plot”) i wybrać opcję “statistics”

Krok 4. Skopiować wartości pierwszych dwóch formantów (column 0 to F1, column 1 to F2) do notatnika lub arkusza kalkulacyjnego.
V. Wykreślanie wyników pomiarów na płaszczyźnie F2-F1
Na podstawie wyników pomiarów można wykreślić różnego rodzaju wykresy, np. popularny “czworobok samogłoskowy”. Wykresy takie można tworzyć za pomocą wielu narzędzi, arkuszy kalkulacyjnych itp.
Krok 1: Proste wykresy F1, F2
Proszę wykonać wykres F1, F2, korzystając z dowolnego narzędzia, np. arkusza kalkulacyjnego Open Office lub Excel. Można też skorzystać z narzędzi dostępnych online, np. https://scatterplot.online/.
Należy zwrócić uwagę, że wykresy na płaszczyźnie F2-F1 często przedstawiają wykres rozrzutu taki, że osie są odwócone (wartości maleją z oddalaniem się od początku układu współrzędnych), a skala jest logarytmiczna.
Krok 2: Czworobok samogłoskowy w R
Jednym z darmowych popularnych pakietów, umożliwiających tworzenie wykresów (a także różnego rodzaju obliczeń statystycznych) jest program statystyczny R.
Dla pomiarów otrzymanych w ramach ćwiczeń:
a) wyniki pomiarów F1 i F2 należy zapisać do pliku, a następnie wszystkie umieścić w jednym arkuszu kalkulacyjnym (np. eksport z Annotation Pro w przypadku sposobu 1, albo ręczne kopiowanie w przypadku sposobu 2);
b) proszę stworzyć wykres formantów na płaszczyźnie F2-F1 korzystając z R;
c) proszę porównać wyniki pomiaru formantów dla obu głosów z średnimi wg Jassema (“Podstawy fonetyki akustycznej”, zob. też niżej). W przypadkach, gdy różnice są bardzo duże należy powtórzyć pomiar / upewnić się, że był prawidłowy.
d) proszę stworzyć raport z wyników swoich pomiarów, który obejmie: wykres wartości średnich F1 i F2 dla obecnych nagrań nałożony na wykres średnich dla języka polskiego wg wyników z publikacji Jassema (1973) oraz komentarz na temat różnic/podobieństw z średnimi dla j. polskiego oraz ewentualne wnioski/interpretacje.
e) sprawdzone średnie wyniki pomiarów proszę podać w ankiecie: Ankieta – Formanty, raport przesłać na adres klessa at amu.edu.pl w wiadomości pod tytułem: FONETYKA_Formanty_Nazwisko_Imię, plik z raportem powinien mieć nazwę: Nazwisko_Imię_Formanty.




# formant data
F1 = c(275,391,630,1020,679,338)
F2 = c(2840, 2360, 2230, 1570, 1100, 789)
names = c(“[i]”,”[y]”,”[e]”,”[a]”,”[o]”,”[u]”)
# linear plot
plot(F2,F1,xlim=c(2900,800),ylim=c(2000,200),type=”n”)
text(F2,F1,names)
# formant data
F1 = c(275,391,630,1020,679,338)
F2 = c(2840, 2360, 2230, 1570, 1100, 789)
names = c(“[i]”,”[y]”,”[e]”,”[a]”,”[o]”,”[u]”)
# logarithmic plot
plot(F2,F1,xlim=c(2900,800),ylim=c(2000,200), log=”xy”)
text(F2,F1,names)
* Uwaga * w zapytaniach po skopiowaniu ich do okna R należy poprawić znaki cudzysłowu na zwykłe.
Wykresy nałożone:


Średnie (min-max) wartości formantów dla języka polskiego:

Producing Simple Graphs with R
Praat User’s Guide: Measuring Duration and Formants (zob. szczególnie rozdz. IV).
Using Praat for Linguistic Research (zob. m.in. 6.6.2 Improving Formant Finding results).
SpeCT – The Speech Corpus Toolkit for Praat (skrypty dla programu Praat).